从数据结构理解 MySQL 联合索引
前言
索引的本质是一种通过特定数据结构来优化数据检索速度的机制。是我们开发岗接触 MySQL 最重要的概念之一,与我们的应用开发息息相关。
结合应用思考
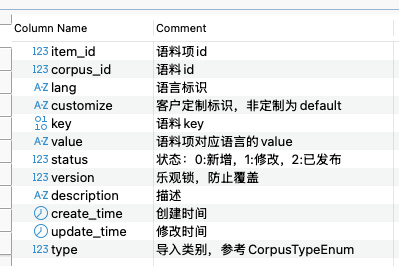
1)在语料平台中的 Item 表中,假设我们的目标是快速搜索 key,只考虑完全匹配的情况下,如何建立索引?
- 索引的字段(业务驱动、是否要覆盖)
- 索引顺序(最左前缀匹配、高选择性或离散性)
2)考虑大批量写的情况下,怎样的索引可以减少性能损耗?
3)高选择性的字段是不是一定排最前?
4)如何在离散性与随机性之间抉择?
1、MySQL 索引的数据结构种类
| 索引类型 | 存储引擎 | 底层数据结构 | 特点与用途 |
|---|---|---|---|
| 普通索引 / 主键 / 唯一索引 | InnoDB | B+Tree | 默认且绝对主流。聚簇索引叶子节点存数据,二级索引叶子节点存主键。 |
| 普通索引 / 主键 / 唯一索引 | MyISAM | B+Tree | 非聚簇索引,叶子节点存数据行的物理地址。 |
| 哈希索引 | Memory | Hash Table | 默认类型,等值查询极快,用于临时表和缓存。 |
| 自适应哈希索引 | InnoDB | Hash Table | 内部自动功能,自动缓存热点数据,加速等值查询。 |
| 全文索引 (FULLTEXT) | InnoDB, MyISAM | 倒排索引 | 解决 LIKE ‘%…%’ 性能问题,用于全文检索。 |
| 空间索引 (SPATIAL) | InnoDB, MyISAM | R-Tree | 专用于地理空间数据类型查询。 |
其他索引数据结构:Skip List跳表、红黑树、BitMap 位图、Trie 前缀树
2、B+树
B+Tree 是多路平衡搜索树,一种专为磁盘等外部存储设备设计的、多路的、平衡的搜索树。它的主要目标是减少磁盘 I/O 次数,从而高效地支持大规模数据的增删改查,尤其是范围查询。
https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
3、从 B+树看联合索引设计原则

最左前缀匹配原则
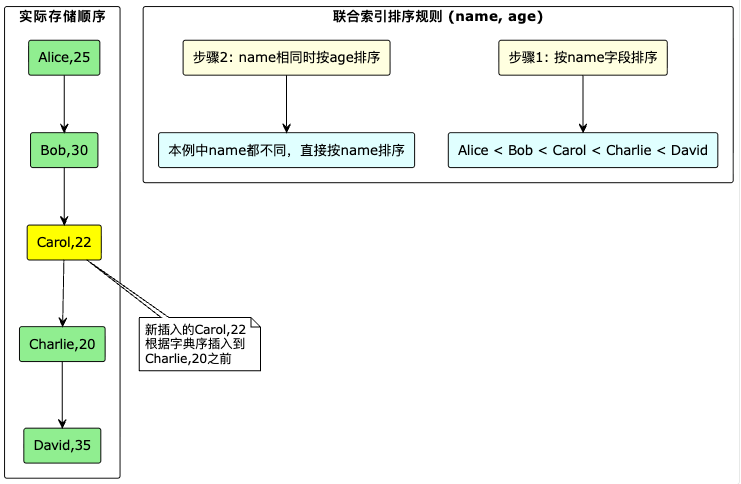
高选择性在前
-
快速过滤:在B+树的早期层次就能大幅缩小搜索范围
-
减少I/O:避免扫描大量无关数据页
-
提高缓存效率:集中访问少量相关页面
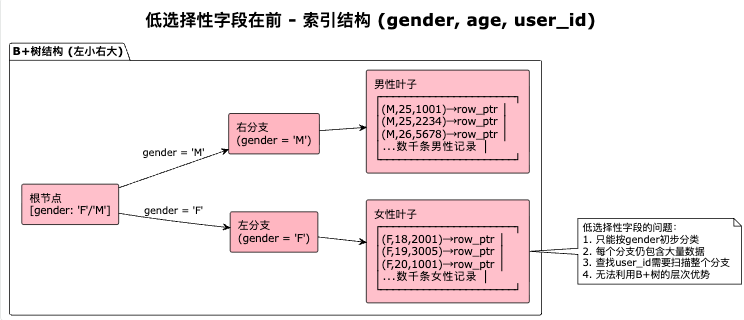
无序字段放后
-
空间局部性:相关数据分散存储,缓存效率低
-
时间局部性:随机访问模式,无法利用预读机制
-
结构局部性:频繁页分裂破坏树的平衡性
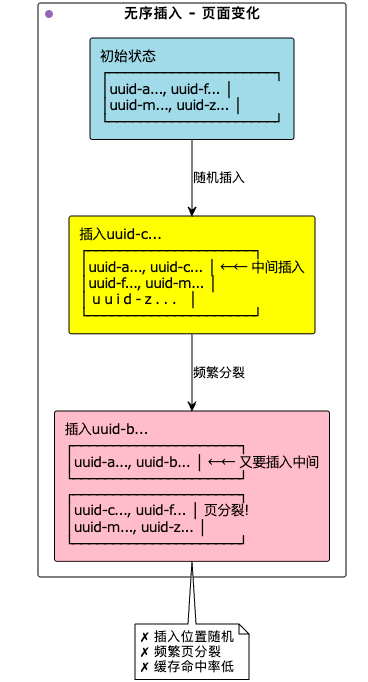
等值查询&范围查询顺序
覆盖索引原则
宽度权衡原则
4、应用
回到应用场景,语料平台上的 corpusId、lang、customize、key 这四个字段的索引顺序应该如何排?
选择性又高到低排序:key > corpusId > lang > customize(读性能最佳)
随机性字段:key > lang > customize > corpusId (写性能最差)
key 作为随机、高选择性字段,如何权衡?

5、实验
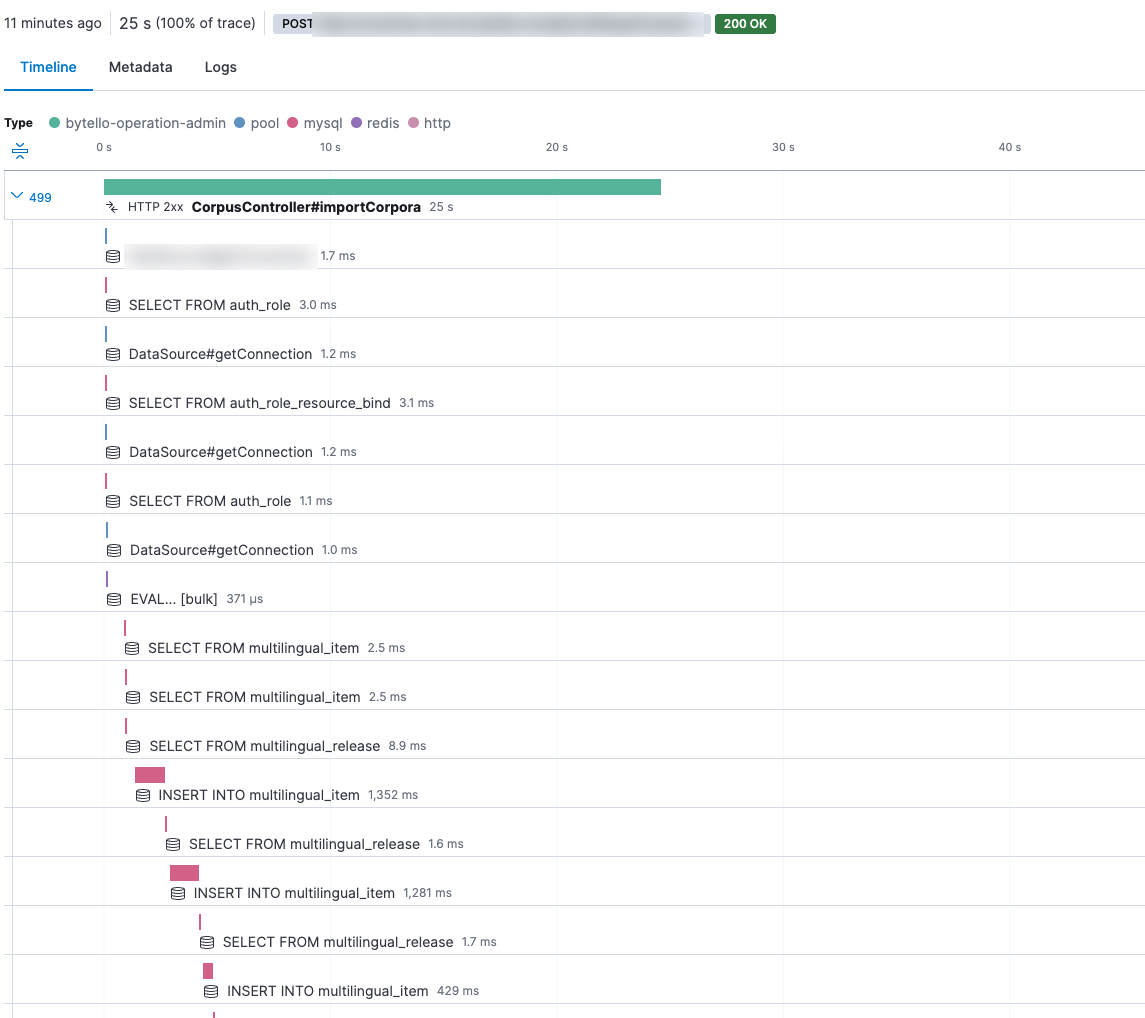
1) 索引顺序:key,lang,customize,corpusId
a. 删除一个项目环境的所有语料
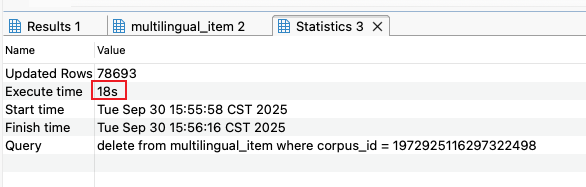
b. 导入 8w 条语料
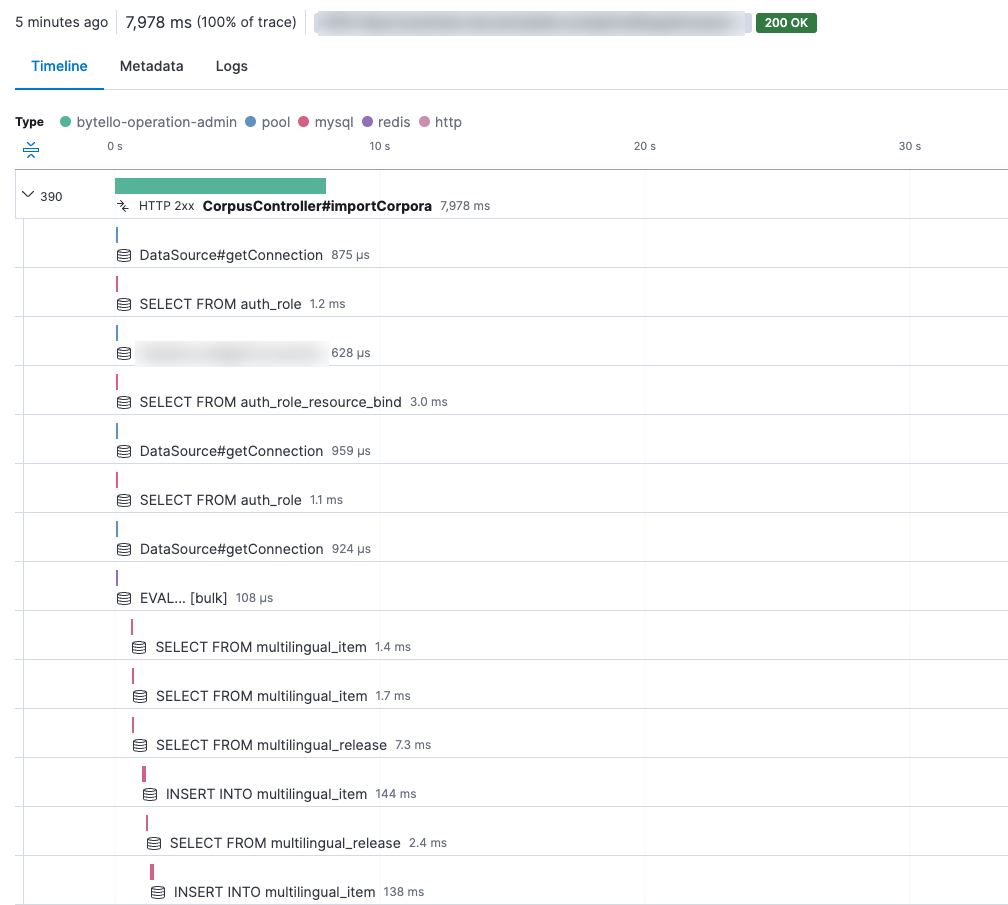
2) 索引顺序:corpusId,lang,customize,key
a. 删除一个项目环境的所有语料
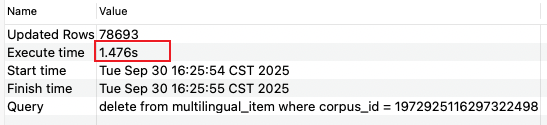
b. 导入 8w 条语料
6、BTW,简单说下语料平台写场景下的并发控制机制
问题
如何控制并发,防止 ABA 覆盖,防止死锁?
批量新增或更新
1)方式一:ON DUPLICATE KEY UPDATE
- ON DUPLICATE KEY UPDATE 原理与执行流程
2)方式二:应用层 SELECT + INSERT/UPDATE
锁控制
并发读写有 MySQL 的 MVCC 机制,写冲突需要我们处理:
1、乐观锁 单个写:版本乐观锁(CAS CompareAndSwap,无锁并发)
2、悲观锁 批量写:粒度尽量小,产品-> 项目 ->环境
死锁问题,使用 ON DUPLICATE KEY UPDATE 会带来的问题。对 corpusId 加锁,有用吗?可以防止数据 ABA 覆盖,但是还是有可能死锁(ON DUPLICATE KEY UPDATE 原理问题)。问题大吗?不大,首先并发批量写概率不大,发生了也问题不大,MySQL 检查到死锁快速失败,不会让用户等待,重试即可。