背景
为提高后台整体质量,目前大部分后台系统都接入了 Error 日志监控告警,接入初期产生了非常多的告警,消耗了我们大量的时间去排查。当前线上异常日志排查主要存在以下痛点:
- 服务链路复杂,定位困难: 后台系统通常由众多服务构成(包括上下游依赖),排查一个问题往往需要跨多个监控平台应用、多个集群日志、多个服务进行搜索,并定位代码才能准确定位根源。
- 告警噪音干扰严重: 存在大量 Error 级别的告警日志并非真正的系统异常(例如预期的业务校验失败、可忽略的第三方短暂异常),而是需要调整日志级别或优化处理逻辑。识别此类“非问题”告警并推动修改,同样耗费大量时间。
- 跨团队协作成本高: 当排查指向下游服务或需要其他团队协助时,需耗费大量时间手动整理详细的异常上下文信息(如时间戳、TraceID、关键参数、异常堆栈)并转交给相关方。
- 缺乏智能化辅助: 大部分异常的分析本质上是梳理代码执行链路和业务逻辑。此过程高度依赖人工经验,若能借助 AI 能力智能推导出完整的调用链路、关键变量状态及潜在逻辑缺陷,将极大提升排查效率,甚至在部分场景下自动修复代码解决。
目标
- 建立自动化异常日志分析系统: 构建智能化的日志处理与分析平台,减少人工介入。
- 实现日志到代码的快速精准定位: 将异常日志信息快速关联到对应的代码仓库、文件乃至代码行。
- 显著提升异常排查效率: 缩短单个异常的平均排查时间(MTTR),释放开发运维人力。
- 构建可复用的异常分析知识库: 积累处理经验,形成可检索的知识沉淀,辅助未来同类问题的解决。
方案
1、人工 OR 自动
AI 辅助我们排查问题,主要有两种方式:
| 方案 | 优点 | 缺点 |
|---|---|---|
| 方案一:开发MCP Server,人工将企业 IM 群内的报错信息发给 AI Client,AI 结合接收到的日志内容、关联的代码仓库信息,进行代码定位与异常链路分析,并输出报告。 | 1. 可控性强: 人工筛选关键告警触发分析,避免无效请求。2. 利用成熟能力: 可集成现有 MCP 平台及 Cursor AI 强大的代码分析能力。3. 易于初期试点: 实施复杂度相对较低。 | 1. 依赖人工介入: 仍需人工识别并转发告警信息,无法实现全流程自动化。2. 响应有时延: 依赖于人工操作,响应速度不如自动触发快。3. 上下文可能不全: 人工转发可能遗漏关联日志或上下文信息,影响分析准确性。 |
| 方案二:开发 AI 服务,将Error日志直接上报到AI 服务,利用 AI 自动化分析并输出报告 | 1. 自动化程度高: 无需人工干预,实现告警到分析的自动闭环。 | 1. 初期处理压力大: 线上错误日志量大且繁杂,直接全量上报会造成 AI 服务巨大吞吐压力与分析资源浪费。2. 需完善过滤机制: 必须设计高效的过滤规则,避免无效分析。 |
总结:方案一适合初期试点、或处理复杂低频、需要人工确认的高优先级问题。其优势在于风险可控,能充分利用现有工具链。所以我们可以先采取方案一,人工根据严重程度和优先级识别筛选问题,并发给 AI 分析,后续再使用自动化的方式帮助我们过滤或标注出需要重点关注的Error 异常问题。根据两种方式使用不同的大模型来控制成本。
2、拿到日志后,如何找到对应的代码仓库
方式一:从报错堆栈信息里找到项目三级包名映射到代码仓库
映射关系初始化与更新
部门维护的项目其实有限,可能就几十个,我们可以利用 MCP 扫描 gitlab 今年有 commit 记录的所有项目,加入映射索引文件。达到快速建立索引的目的。并且可以让部门其他成员分享出他们的映射表,让 AI 帮我们合并到自己的映射表里。
映射规则
1)使用三级包名,如 com.bytello.account,一般就能对应一个项目,如果有多个项目使用了这个包名,则让用户干预进行选择。
2)如果找不到,那问题排查就到此为止了,很有可能排查到的下游服务是其他部门或其他 bg 的服务了,我们把 AI 总结的内容抛出去就行了。
方式二:使用日志里的 container.image.name 镜像名称解析出项目名
应用日志里有一个镜像名称字段,我们可以通过该字段获取到镜像仓库名称。镜像仓库名称和 gitlab 仓库名称可能有区别,比如,镜像名称是 registry.example.com/
对比
| 方案 | 优点 | 缺点 |
|---|---|---|
| 从报错堆栈信息里去项目三级包名映射到代码仓库 | 匹配比较精确 | 处理起来比较麻烦,获取到的仓库有限 |
| 使用日志里的 container.image.name 镜像名称解析出项目名 | 可以获取到自己有权限的所有仓库代码 | 没办法处理镜像仓库名称和 gitlab 仓库名称完全不一致的项目。 |
总结
综上,采取方案二,局限性没有大,不依赖本地映射配置,也可以获取到自己有权限的所有仓库。
3、怎么引导 AI 将所有工具串联起来排查问题?
提供一个 Tool 返回指导框架 Prompt,所有排查操作都先经过过去 Prompt,然后再继续排查。
那么如何提高稳定性,有时 AI 并不会按照 Prompt 引导的流程去执行?
可以通过在每个阶段的完成提供下一步的 Prompt 提示,比如在查询日志的 Tool 里根据不同的查询结果附加不同 Prompt,如果成功查询出日志,Prompt 提示下一步进行代码分析。如果没查出结果,可以附加扩大时间范围重新查询等提示。
4、优化
如果错误是当前 Cursor 打开的项目,直接在当前项目代码进行排查,这样可以利用到 Cursor 的文件索引,而不需要去查 Gitlab 仓库代码,那怎么判断报错的项目是不是当前项目?
通过 git 命令查询当前项目仓库名,对应日志里的 container.image.name 镜像名称,如果项目名大致一直(比如大小写区别,分隔符不同等,可以通过 prompt 实现),则认为是同个项目。
MCP 流程图
1、系统架构概览
30+ 项目管理工具] L[Kibana 工具
Cookie 管理工具] M[日志搜索工具
应用/Nginx 日志搜索] N[问题分析工具
分析指导框架] end subgraph "API 客户端层" G[GitLabClient
GitLab API 封装] H[KibanaClient
Kibana API 封装] I[ElasticsearchClient
ES 查询封装] J[KibanaClusterManager
多集群管理] end subgraph "配置管理层" D[GitLab 配置
GITLAB_CONFIG] E[Kibana 集群配置
KIBANA_CLUSTERS] F[日志配置
logging_config] end subgraph "外部服务层" O[GitLab 服务器
代码仓库] P[Kibana 集群
新加坡/德国/美国] Q[Elasticsearch
日志存储] end %% 服务层到工具层(工具注册) C -.-> K C -.-> L C -.-> M C -.-> N %% 工具层调用API客户端层 K --> G L --> H M --> I M --> J %% API客户端层获取配置 G --> D H --> E I --> E J --> E %% API客户端层访问外部服务 G --> O H --> P I --> Q J --> P %% 样式定义 classDef entryLayer fill:#e1f5fe classDef serviceLayer fill:#f3e5f5 classDef toolLayer fill:#fce4ec classDef clientLayer fill:#fff3e0 classDef configLayer fill:#e8f5e8 classDef externalLayer fill:#f1f8e9 class A,B entryLayer class C serviceLayer class K,L,M,N toolLayer class G,H,I,J clientLayer class D,E,F configLayer class O,P,Q externalLayer end
2、数据流向图
3、详细运行时流程
4、Kibana 日志搜索流程
最终效果
我们把群里报的告警直接发给 Cursor,首先会获取分析指导框架,然后进入排查流程。
1、第一步会根据我们发送的内容提取关键信息,然后查询应用日志。
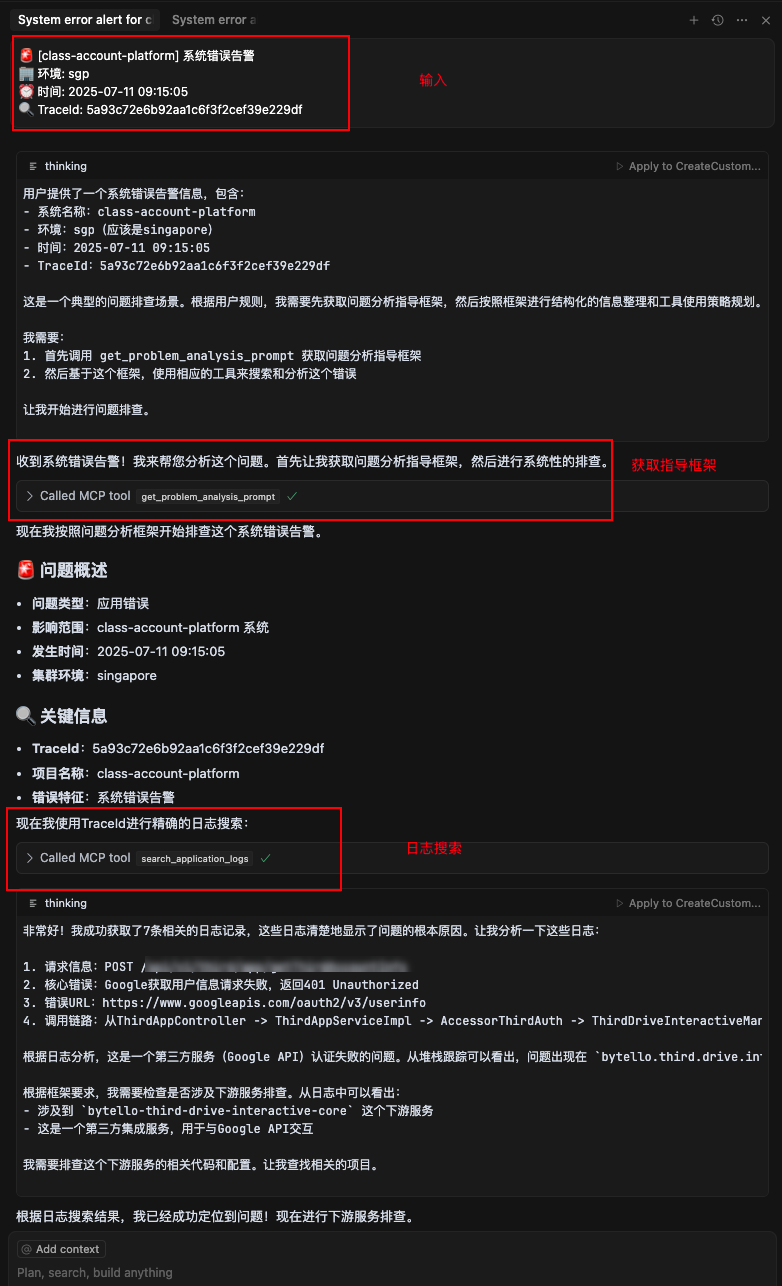
2、从应用日志分析错误,分析出应用里的调用链路。如果涉及调用其他服务,会查找相关服务的代码。
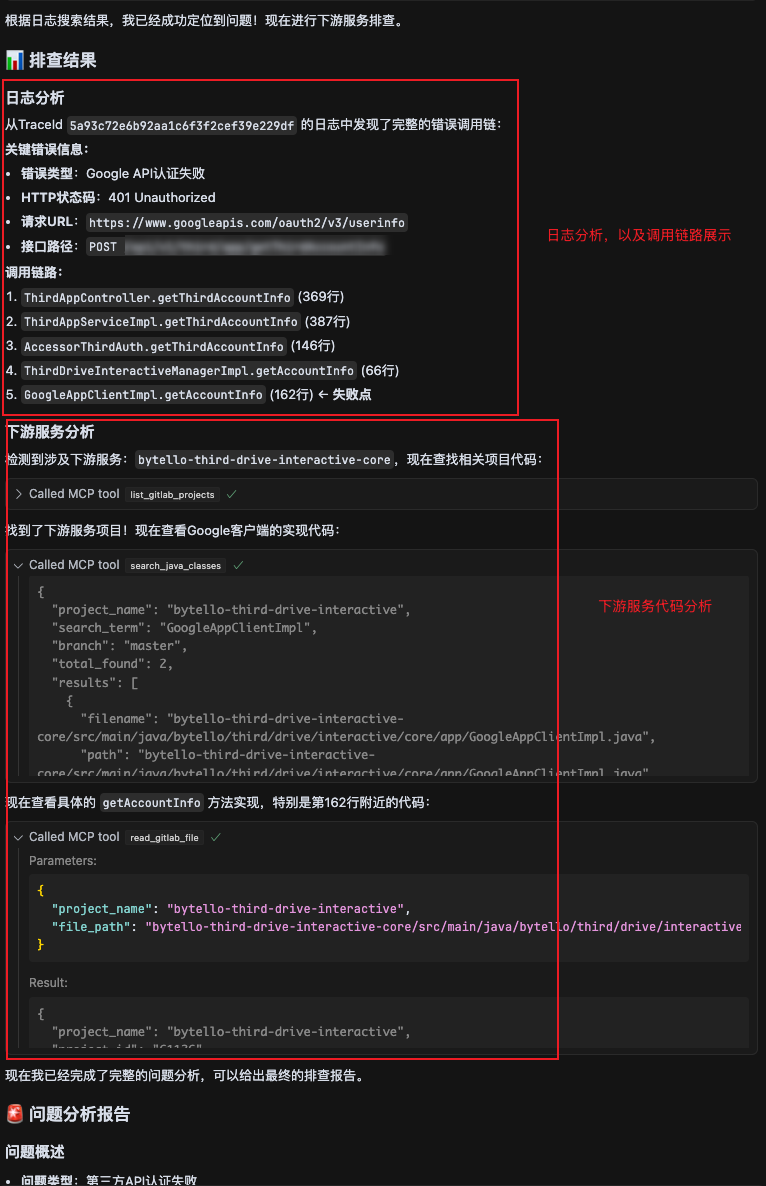
3、输出分析报告,总结错误原因。
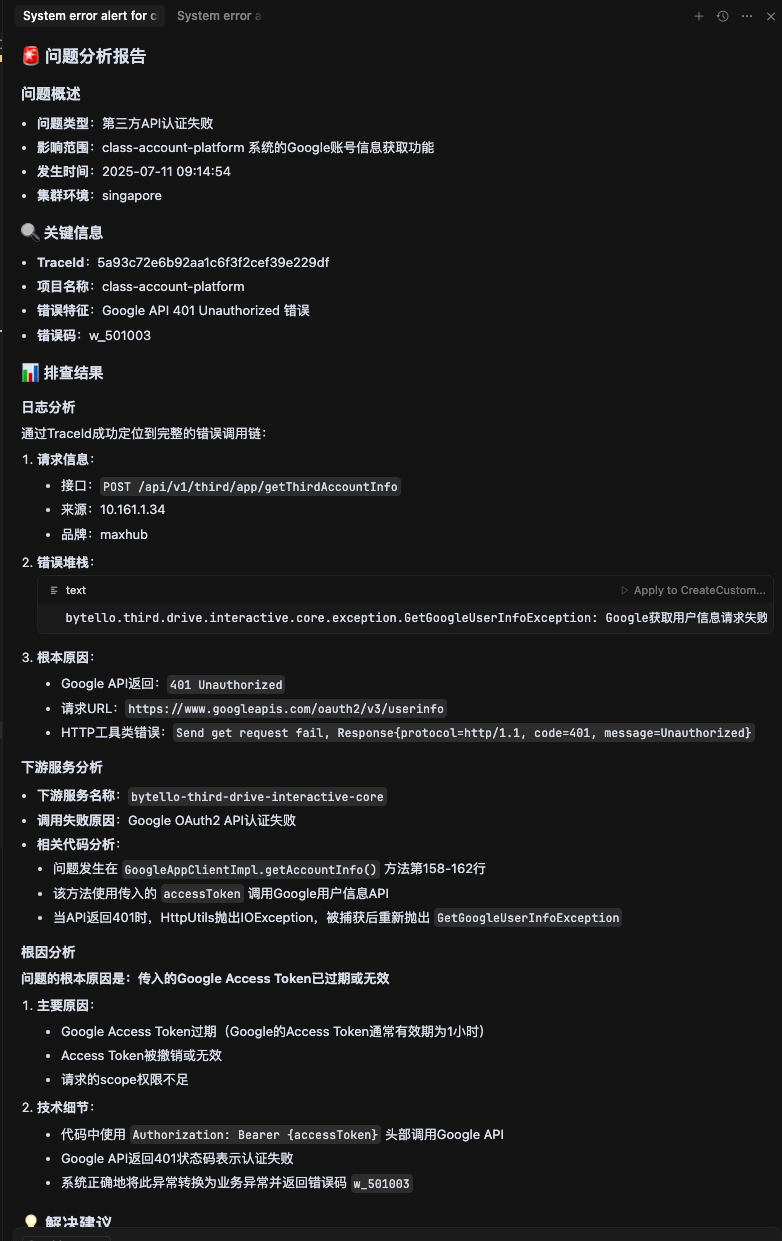
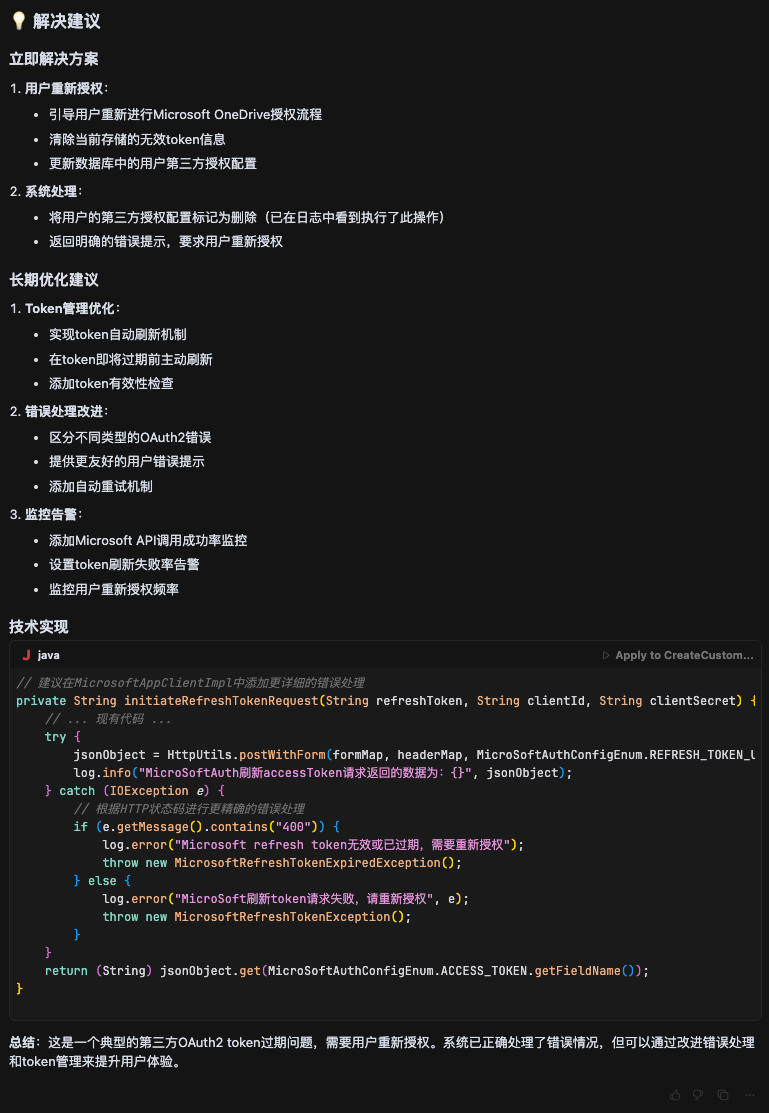
4、提出解决建议,最终查出是业务正常情况。
总结
我们可以看到它帮我们查找了指定集群日志,给出清晰的调用链路,以及相关的代码分析,包括下游服务。帮助我们确定告警是不是无效的告警,以及帮助我们节省大量的问题排查时间,我们也可以根据调用链路自己更快地排查解决问题。
不足之处:目前还没法排查解决复杂问题,比如数据库相关的问题、涉及接口性能问题、复杂路由问题(MDC),后续可以接入数据库、APM 等工具,使问题排查更加全面
未来展望
1、结合更多工具来帮助 AI 更加精准地定位问题,以及提供给我们更多的上下文信息,比如:MySQL查询,APM 日志等等
2、结合自动化的方式帮助我们过滤或标注出需要重点关注的 Error 异常问题。根据两种方式使用不同的大模型来控制成本,大致会是这样一个架构:
- Error 日志上报 ——> 低成本 AI + 知识库 ——> 过滤与分析 ——> 转发企业 IM 并标注重点异常 ——> 点击附带链接跳转报告
- Cursor + MCP ——> ES + Gitlab ——> 分析报告